在本文中,我将会研究C++中哈希表的实际实现以理解其瓶颈。哈希函数是CPU密集型的并且应该为此优化。然而,大部分哈希表的内部机制只关心内存效率和I/O访问,这将是本文主要注意的东西。我将会研究三个不同的哈希表的C++实现,既有内存中的又有硬盘上的,并看看数据是怎么组织和访问的。本文将包括:
- 哈希表
1.1 哈希表简介
1.2 哈希函数
- 实现
2.1 TR1的unordered_map
2.2 SparseHash的dense_hash_map
2.3 Kyoto Cabinet的HashDB
- 结论
- 参考文献
1.哈希表
1.1 哈希表简介
哈希表可以认为是人类所知最为重要的数据结构 .
— 斯蒂夫 耶奇
哈希表可以高效的访问关联数据。每个条目都有一对对应的键名和键值,并且能仅通过键名来快速的取回和赋值。为了达到这个目的,键名通过哈希函数进行哈希,以将键名从原始形式转换为整数。此整数之后作为索引来得到要访问的条目的值所在的bucket在bucket数组中的地址。很多键名可以被哈希为相同的值,这表示这些key在bucket数组中回出现碰撞。有数种方法解决碰撞,如使用链表的分离链表(separate chaining 亦称开链或单独链表)或自平衡二叉树或线性或者二次探测的开放寻址。
从现在开始,我默认你知道什么是哈希表。如果你认为自己需要温习一下知识,Wikipedia的“Hash table”词条[1](及其底部的扩展链接一节)和Cormen 等人写的Introduction to Algorithms一书中Hash table一章[2]都是很好的参考文献。
1.2 哈希函数
哈希函数的选择相当重要。一个好哈希函数的基本需求是输出的哈希值比较均匀。这样可以使碰撞的发生最小化,同时使得各个bucket中碰撞的条目比较平均。
可用的哈希函数有很多,除非你确切的知道数据会变成什么样子,最安全的方法是找一个能够将随机数据分布均匀的哈希函数,如果可能的话符合雪崩效应[3]。有少数人对哈希函数做过比较[4] [5] [6] [7],而他们的结论是MurmurHash3 [8]和CityHash [9] 是在写本文的时候最好的哈希函数。
2.实现
和哈希函数的比较一样,只有很少比较各个C++的内存哈希表库性能的博文。我见到的最出名的是Nick Welch 的“Hash Table Benchmarks” [10],和Jeff Preshing 的“Hash Table Performance Tests” [11]。而其他文章也值得一看[12] [13] [14]。从这些比较中,我发现两个研究起来比较有意思的部分:GCC的TR1的unordered_map和SparseHash 库(以前叫Google SparseHash)的dense_hash_map,我将会在下文中介绍他们。另外,我同样会描述Kyoto Cabinet中HashDB的数据结构。显然因为unordered_map 和dense_hash_map是内存哈希表,不会像HashDB那样和我的键值对存储相关。尽管如此,稍微看一下其内部数据结构的组织和其内存模式也是很有意思的。
在下述三个哈希表库的描述中,我的通用示例是把一组城市名作为键名其各自的GPS坐标作为键值。unordered_map的源代码可以在GCC代码中作为libstdc++-v3的一部分找到。我将会着眼于GCC v4.8.0的libstdc++-v3 release 6.0.18[15],SparseHash v2.0.2中的dense_hash_map[16],和Kyoto Cabinet v1.2.76中的HashDB[17]。
Matthew Austern的“A Proposal to Add Hash Tables to the Standard Library (revision 4)”一文[18]和SparseHash的“Implementation notes”页面[19]也有很有意思的关于哈希表实现的讨论。
2.1 TR1中的unordered_map
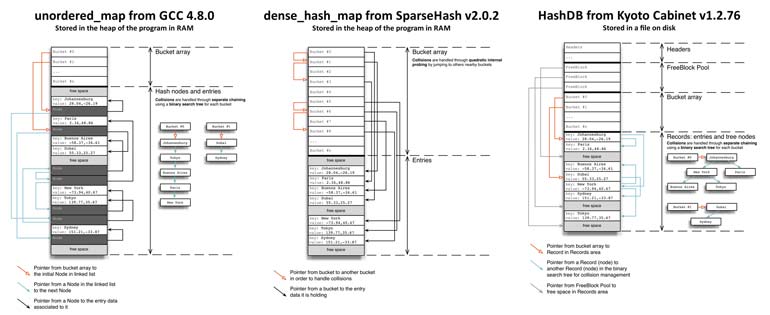
TR1的unordered_map提供了一个用链表(分离链)解决碰撞的哈希表。Bucket数组位于堆中,并且基于哈希表的负载系数自动调整大小。而bucket的链表则是用叫做_Hash_node的节点结构体创建。
/* from gcc-4.8.0/libstdc++-v3/include/tr1/hashtable_policy.h */
template
struct _Hash_node<_Value, false>
{
_Value _M_v;
_Hash_node* _M_next;
};
如果键和值都是整型,其可以直接存储在_M_v结构体中。否则将会存储指针,同时需要额外的内存。Bucket数组是在堆中一次性分配的,但并不分配节点的空间,节点的空间是通过各自调用C++内存分配器来分配的。
/* from gcc-4.8.0/libstdc++-v3/include/tr1/hashtable.h */
Node* _M_allocate_node(const value_type& __v)
{
_Node* __n = _M_node_allocator.allocate(1);
__try
{
_M_get_Value_allocator().construct(&__n->_M_v, __v);
__n->_M_next = 0;
return __n;
}
__catch(...)
{
_M_node_allocator.deallocate(__n, 1);
__throw_exception_again;
}
}
因为这些节点是各自分配的,分配过程中可能浪费大量的内存。这取决于编译器和操作系统使用的内存分配过程。我甚至还没说每次分配中系统执行的调用。SGI哈希表的原始实现为这些节点做了一些资源预分配工作,但这个方法没有保留在TR1的 unordered_map实现中。
下文的图5.1展示了TR1中unordered_map的内存和访问模式。让我们来看看当我们访问和键名“Johannesburg”相关的GPS坐标的时候会发生什么。这个键名被哈希并映射到了bucket #0。在那我们跳到了此bucket的链表的第一个节点(bucket #0左边的橙色箭头),我们可以访问堆中存储了键“Johannesburg”所属数据的内存区域(节点右侧的黑色箭头)。如果键名所指向的第一个节点不可用,就必须遍历其他的节点来访问。
至于CPU性能,不能指望所有的数据都在处理器的同一个缓存行中。实际上,基于bucket数组的大小,初始bucket和初始节点不会在同一个缓存行中,而和节点相关的外部数据同样不太可能在同一个缓存行中。而随后的节点机器相关数据同样不会在同一个缓存行中并且需要从RAM中取回。如果你不熟悉CPU优化和缓存行,维基上的“CPU Cache”文章是一个很好的介绍20。
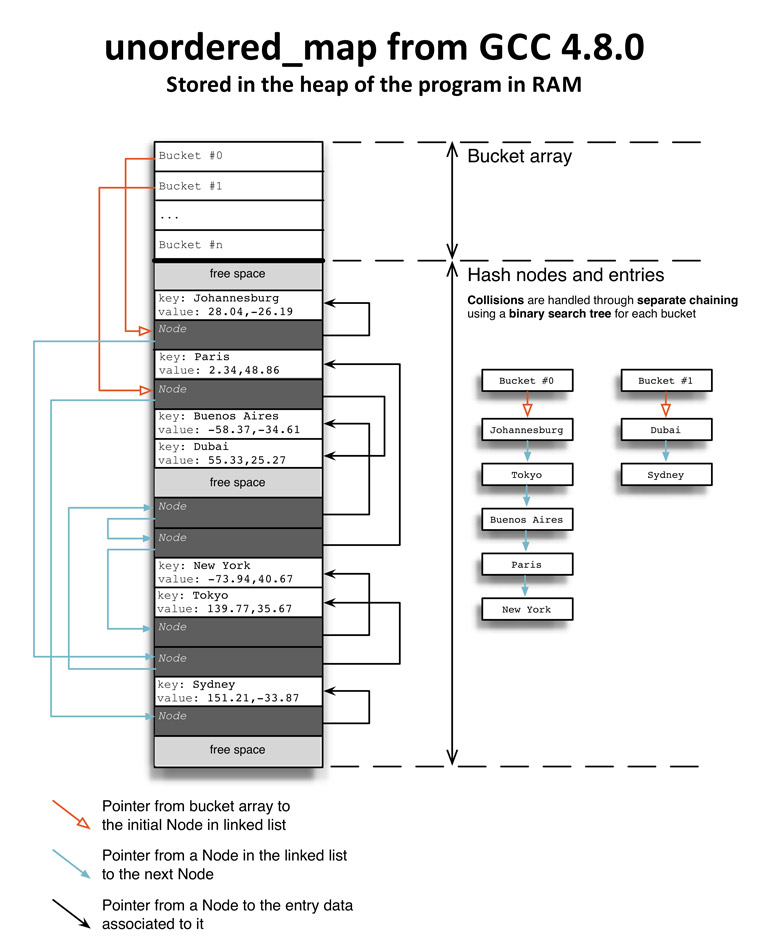
图5.1
2.2 SparseHash的dense_hash_map
SparseHash库提供了两个哈希表实现,sparse_hash_map和dense_hash_map。sparse_hash_map在低成本下提供了出色的内存占用,并使用一个特定的数据结构sparsetable来打到这个目的。在SparseHash的“Implementation notes”页面19可以找到更多关于sparsetables 和sparse_hash_map的信息。在此我只讨论dense_hash_map。
dense_hash_map用二次内部探测处理碰撞。和unordered_map一样,bucket数组也是在堆中一次分配,并基于哈希表的负载因子调整大小。bucket数组的元素是std::pair的实例,其中Key和T分别是键名和键值的模版参数。在64位架构下储存字符串的时候,pair的实例大小是16字节。
下文的图5.2是dense_hash_map内存和访问模式的展示。如果我们要寻找“Johannesburg”的坐标,我们一开始会进入bucket #0,其中有“Paris”(译注:图上实际应为“Dubai”)的数据(bucket #0右侧的黑色箭头)。因此必须探测然后跳转到bucket (i + 1) = (0 + 1) = 1(bucket #0左侧的橙色箭头),然后就能在bucket #1中找到“Johannesburg”的数据。这看上去和unordered_map中做的事情差不多,但其实完全不同。当然,和unordered_map一样,键名和键值都必须存储在分配于堆中的内存,这将导致对键名和键值的寻找会使缓存行无效化。但为碰撞的条目寻找一个bucket相对较快一些。实际上既然每个pair都是16字节而大多数处理器上的缓存行都是64字节,每次探测就像是在同一个缓存行上。这将急剧提高运算速度,与之相反的是unordered_map中的链表需要在RAM中跳转以寻找余下的节点。
二次内部探测提供的缓存行优化使得dense_hash_map成为所有内存哈希性能测试中的赢家(至少是在我目前读过的这些中)。你应该花点时间来看看Nick Welch的文章“Hash Table Benchmarks” 10。
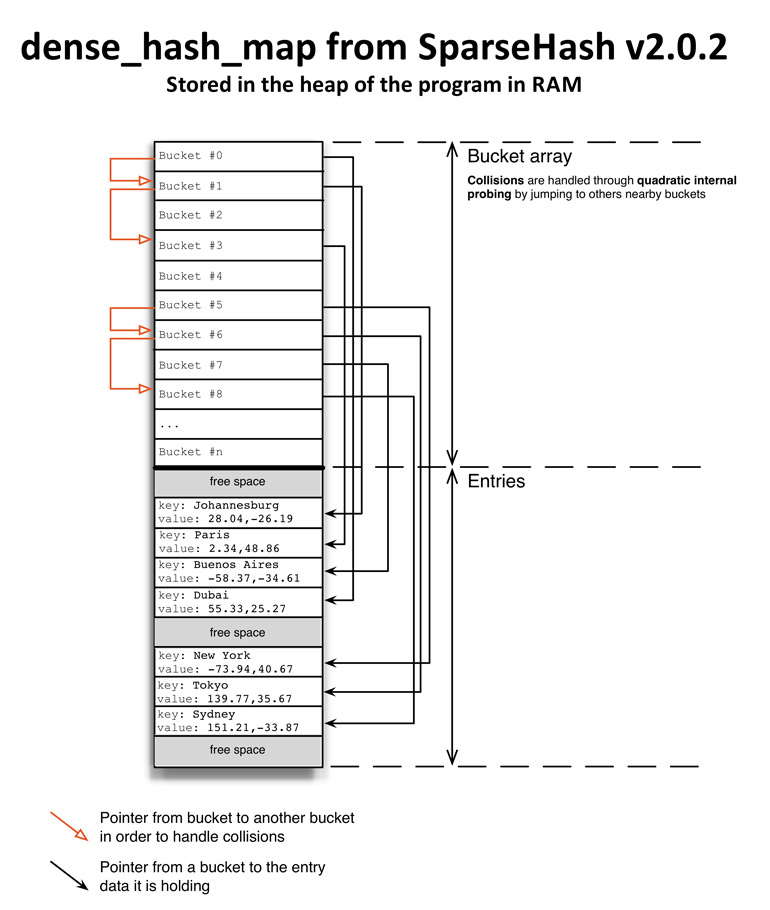
图5.2
2.3 Kyoto Cabinet的HashDB
Kyoto Cabinet实现了很多数据结构,其中就有哈希表。这个哈希表HashDB虽然有一个选项可以用来把他用作代替std::map的内存哈希表,但其是设计用于在硬盘上持久化的。哈希表的元数据和用户数据一起用文件系统依次存储在硬盘上唯一的文件中。
Kyoto Cabinet使用每个bucket中独立的二叉树处理碰撞。Bucket数组长度固定且不改变大小,无视负载因子的状态。这是Kyoto Cabinet的哈希表实现的主要缺陷。实际上,如果数据库创建的时候定义的bucket数组的长度低于实际需求,当条目开始碰撞的时候性能会急剧下降。
允许硬盘上的哈希表实现改变bucket数组大小是很难的。首先,其需要bucket数组和条目存储到两个不同的文件中,其大小会各自独立的增长。第二,因为调整bucket数组大小需要将键名重新哈希到新bucket数组的新位置,这需要从硬盘中读取所有条目的键名,这对于相当大的数据库来说代价太高以至于几乎不可能。避免这种重新哈希过程的一种方法是,存储哈希后键名的时候每个条目预留4或8个字节(取决于哈希是长度32还是64 bit)。因为这些麻烦事,固定长度的bucket数组更简单,而Kyoto Cabinet中采用了这个方法。
图5.3显示出文件中存储的一个HashDB的结构。我是从calc_meta()方法的代码,和kchashdb.h尾部HashDB类中属性的注释中得到的这个内部结构。此文件以如下几个部分组织:
- 头部有数据库所有的元数据
- 包含数据区域中可用空间的空块池
- bucket数组
- 记录(数据区域)
一条记录包含一个条目(键值对),以及此独立链的二叉树节点。这里是Record结构体:
/* from kyotocabinet-1.2.76/kchashdb.h */
/**
* Record data.
*/
struct Record {
int64_t off; ///< offset
size_t rsiz; ///< whole size
size_t psiz; ///< size of the padding
size_t ksiz; ///< size of the key
size_t vsiz; ///< size of the value
int64_t left; ///< address of the left child record
int64_t right; ///< address of the right child record
const char* kbuf; ///< pointer to the key
const char* vbuf; ///< pointer to the value
int64_t boff; ///< offset of the body
char* bbuf; ///< buffer of the body
};
图5.4可以看到记录在硬盘上的组织。我从kchashdb.h中的write_record()方法中得到组织方法。注意其和Record结构体不同:保存在硬盘上的目标是最小化硬盘占用,然而结构体的目标是使记录在编程的时候用起来比较方便。图5.4的所有变量都有固定长度,除了key、value、 和padding,其当然是取决于数据条目中数据的尺寸。变量left 和right是二叉树节点的一部分,储存文件中其他记录的offset。
图5.3

图5.4
如果我们要访问键名"Paris"的键值,一开始要获得相关bucket的初始记录,在本例中是bucket #0.。然后跳转到此bucket二叉树的头节点(bucket #0右侧的橙色箭头),其保存键名为"Johannesburg".的数据。键名为"Paris"的数据需要通过当前节点的右侧节点来访问("Johannesburg"记录右侧的黑色箭头)。二叉树需要一个可比较的类型来对节点分类。这里用的可比较类型是用fold_hash()方法将哈希过的键名缩减得到的。
/* from kyotocabinet-1.2.76/kchashdb.h */
uint32_t fold_hash(uint64_t hash) {
_assert_(true);
return (((hash & 0xffff000000000000ULL) >> 48) | ((hash & 0x0000ffff00000000ULL) >> 16)) ^
(((hash & 0x000000000000ffffULL) << 16) | ((hash & 0x00000000ffff0000ULL) >> 16));
}
把数据条目和节点一起存储在单一记录中,乍一看像是设计失误,但其实是相当聪明的。为了存储一个条目的数据,总是需要保持三种不同的数据:bucket、碰撞和条目。既然bucket数组中的bucket必须顺序存储,其需要就这样存储并且没有任何该进的方法。假设我们保存的不是整型而是不能存储在bucket中的字符或可变长度字节数组,这使其必须访问此bucket数组区域之外的其他内存。这样当添加一个新条目的时候,需要即保存冲突数据结构的数据,又要保存该条目键名和键值的数据。
如果冲突和条目数据分开保存,其需要访问硬盘两次,再加上必须的对bucket的访问。如果要设置新值,其需要总计3次写入,并且写入的位置可能相差很远。这表示是在硬盘上的随机写入,这差不多是I/O的最糟糕的情况了。现在既然Kyoto Cabinet的HashDB中节点数据和条目数据存储在一起,其就可以只用一次写入写到硬盘中。当然,仍然必须访问bucket,但如果bucket数组足够小,就可以通过操作系统将其从硬盘中缓存到RAM中。如规范中"Effective Implementation of Hash Database"一节17声明的,Kyoto Cabinet可能采用这种方式。
然而在硬盘上用二叉树存储条目需要注意的一点是,其会降低读取速度,至少当碰撞出现的时候会是这样。实际上,因为节点和条目存储在一起,处理一个bucket中的碰撞实际上是在一个二叉树中寻找要找的条目,这可能需要大量的对硬盘的随机读取。这可以让我们理解当条目的数量超过bucket数量时Kyoto Cabinet的性能急剧下降的原因。
最后,因为所有的东西都是存在文件中,Kyoto Cabinet是自己处理内存管理,而非像unordered_map 和dense_hash_map那样交给操作系统处理。FreeBlock结构体保存着和文件中空闲空间的信息,其基本上是offset和大小,如下:
/* from kyotocabinet-1.2.76/kchashdb.h */
/**
* Free block data.
*/
struct FreeBlock {
int64_t off; ///< offset
size_t rsiz; ///< record size
/** comparing operator */
bool operator <(const FreeBlock& obj) const {
_assert_(true);
if (rsiz < obj.rsiz) return true;
if (rsiz == obj.rsiz && off > obj.off) return true;
return false;
}
};
所有的FreeBlock实例都加载在std::set中,其可以像fetch_free_block()方法中那样使用std::set的upper_bound()方法来释放内存块,从而实现“最佳拟合”的内存分配策略。当可用空间显得过分细碎或者FreeBlock池中没有空间了,文件将进行碎片整理。此碎片整理过程通过移动各条记录来减少数据库文件的整体大小。
3.结论
本文中,我展示了三个不同哈希表库的数据组织和内存访问模式。TR1的unordered_map和SparseHash的dense_hash_map是在内存中的,而Kyoto Cabinet的HashDB是在硬盘上的。此三者用不同的访问处理碰撞,并对性能有不同的英雄。将bucket数据、碰撞数据和条目数据各自分开将影响性能,这是unordered_map中出现的情况。如dense_hash_map及其二次内部探测那样,将碰撞数据和bucket存储在一起;或者像HashDB那样,将碰撞数据和条目数据存储在一起都可以大幅提高速度。此两者都可以提高写入速度,但将碰撞数据和bucket存储在一起可以使读取更快。
如果让我说从这些哈希表中学到的最重要的东西是什么的话,我会说在设计哈希表的数据组织的时候,首选的解决方案是将碰撞数据和bucket数据存储在一起。因为即便是在硬盘上,bucket数组和碰撞数据也会相当小,足够它们存储在RAM中,随机读取的花费将会比在硬盘上低得多。
4.参考文献
[1] http://en.wikipedia.org/wiki/Hash_table
[2] http://www.amazon.com/Introduction-Algorithms-Thomas-H-Cormen/dp/0262033844/
[3] http://en.wikipedia.org/wiki/Avalanche_effect
[4] http://blog.reverberate.org/2012/01/state-of-hash-functions-2012.html
[5] http://www.strchr.com/hash_functions
[6] http://programmers.stackexchange.com/questions/49550/which-hashing-algorithm-is-best-for-uniqueness-and-speed/145633#145633
[7] http://blog.aggregateknowledge.com/2012/02/02/choosing-a-good-hash-function-part-3/
[8] https://sites.google.com/site/murmurhash/
[9] http://google-opensource.blogspot.fr/2011/04/introducing-cityhash.html
[10] http://incise.org/hash-table-benchmarks.html
[11] http://preshing.com/20110603/hash-table-performance-tests
[12] http://attractivechaos.wordpress.com/2008/08/28/comparison-of-hash-table-libraries/
13 http://attractivechaos.wordpress.com/2008/10/07/another-look-at-my-old-benchmark/
[14] http://blog.aggregateknowledge.com/2011/11/27/big-memory-part-3-5-google-sparsehash/
[15] http://gcc.gnu.org/
[16] https://code.google.com/p/sparsehash/
[17] http://fallabs.com/kyotocabinet/spex.html
[18] http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2003/n1456.html
[1\9] http://sparsehash.googlecode.com/svn/trunk/doc/implementation.html
[20] http://en.wikipedia.org/wiki/CPU_cache
There are comments.